
引言
在人工智能技术飞速发展的今天,阿里云的最新动作无疑引起了广泛关注。他们开源了一款名为Qwen2.5-Omni-7B的模型,这款模型被誉为通义千问系列中的首个端到端全模态大模型。它不仅在智能语音应用领域引起了轰动,也为未来的人工智能发展带来了新的可能性。让我们一起来深入了解这一技术突破,探讨其背后的原理、应用场景以及未来的发展方向。
模型介绍
核心技术与架构
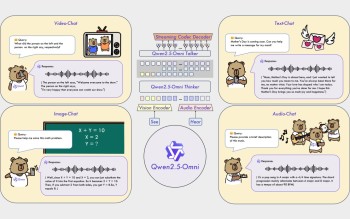
Qwen2.5-Omni-7B是一款规模达70亿参数的大型模型,基于Transformer架构。它融合了文本、图像、音频和视频等多种输入形式,实现了全模态的处理能力。Transformer架构的核心在于其自注意力机制,能够有效地捕捉输入数据中的长距离依赖关系,从而提升模型的理解和生成能力。
多模态处理能力
Qwen2.5-Omni-7B的多模态处理能力使其在多种任务中表现出色。用户可以通过这款模型进行语音识别、图像识别、情感分析等多种人工智能任务。例如,在语音识别方面,模型可以准确地将口语转化为文字,并在情感分析中识别出语音中的情感色彩。而在图像识别方面,模型可以识别出图像中的物体、场景和动作,并进行相应的分类和标注。
开源影响
行业反响
阿里云的开源举措在业界引起了热烈讨论。网友们纷纷表示,Qwen2.5-Omni-7B的开源是一次真正的技术炸弹,让人们看到了阿里云在人工智能领域的领先地位。此举也被认为是对OpenAI的一次挑战,展示了中国企业在人工智能领域的实力和创新能力。
技术挑战与机遇
开源不仅是技术的分享,更是对行业的一次巨大挑战。Qwen2.5-Omni-7B的开源为开发者提供了一个强大的工具,但同时也带来了新的技术难题。例如,如何在有限的计算资源下高效地运行和部署这款模型?如何确保模型的安全性和隐私保护?这些问题都需要行业共同努力去解决。
应用场景
智能语音应用
在智能语音应用领域,Qwen2.5-Omni-7B具有广泛的应用前景。例如,智能助手可以利用这款模型进行更加自然和智能的语音交互,提升用户体验。此外,智能家居设备也可以利用这款模型进行语音控制,实现更加便捷的家居管理。
视频通话与手机应用
除了智能语音应用,Qwen2.5-Omni-7B还可以被运用在视频通话和手机应用中。在视频通话中,模型可以实现AI视频通话功能,让用户体验更加智能化的沟通方式。例如,模型可以自动识别视频中的语音和图像,并进行实时翻译和字幕生成。而在手机应用中,模型可以为用户提供更加便捷的人工智能服务,例如智能语音输入、图像识别等。
未来展望
技术创新与发展
随着Qwen2.5-Omni-7B模型的开源,人们对人工智能技术的发展充满了期待。阿里云以及其他人工智能领域的参与者将会通过这个开源模型开展更多创新性的应用,并不断推动人工智能技术的发展。例如,未来可能会有更多的多模态模型被开发出来,进一步提升人工智能的理解和生成能力。
社会影响与应用
人工智能技术的发展不仅仅是技术上的突破,更是对社会的深远影响。Qwen2.5-Omni-7B模型的开源为智能化生活带来了新的可能性。例如,在医疗领域,模型可以辅助医生进行病情诊断和治疗方案的制定;在教育领域,模型可以为学生提供个性化的学习辅导;在娱乐领域,模型可以创作出更加智能化的内容,提升用户的娱乐体验。
结语
通过这次阿里云开源的Qwen2.5-Omni-7B模型,我们看到了人工智能技术的巨大潜力,也期待着在未来更多相关技术的突破和创新。这款模型不仅在智能语音应用领域具有广泛应用前景,还为多模态处理和智能化生活带来了新的可能性。让我们共同期待,人工智能技术将如何改变我们的生活,带来更加智能和便捷的未来。






